Elasticsearch
Apache Lucene 기반의 오픈소스 검색엔진
Apache Lucene이 Java로 개발되어 있다 보니, Elasticsearch로 Java로 개발 됨
특징
오픈소스
elastic 제품들은 오픈소스로 제공되며, 깃 헙 저장소에 소스를 공유하고 있다.
elastic
elastic has 447 repositories available. Follow their code on GitHub.
github.com
역정규화 (inverted index)
RDB는 테이블 형태로 데이터를 저장하며, 열을 기준으로 인덱스를 생성한다.
검색 시에는 like 검색을 하여 한 줄씩 검사하여 결과값을 가지고 온다.
하나씩 검사하다 보니 데이터가 많아질수록 속도가 점점 느려진다는 단점이 있다

반면, elasticsearch는 텍스트를 모두 뜯어 검색어 사전을 만든다.
- 검색어의 기본 단위를 Term이라 부름
Term을 기준으로 doc의 인덱스를 가리킨다. 이렇게 RDB와는 반대 구조를 가지기 때문에 역정규화(inverted index)라 한다
term을 이용하여 검색하다 보니 굉장히 빠른 속도로 검색할 수 있는 장점이 있다

풀 텍스트 검색이 가능
위 내용처럼 elasticsearch는 역정규화 방식으로 데이터를 색인하여 저장한다. 그리고 이렇게 가공된 텍스트를 검색하는데 이를 풀 텍스트 검색 (Full Text Search)라고 함
검색 최적화
elasticsearch에서는 삽입/수정과 같은 작업은 비싼 비용을 가진 작업이다.
elasticsearch는 검색에 최적화되어 있어서 방대한 양의 데이터를 신속하게 검색하기 좋다. 그래서, 특징을 잘 이해하고 검색이 많은 서비스에 사용하는 것이 좋다
실시간 분석
거의 실시간에 가까운 속도로 색인된 데이터의 검색이 가능
RDBMS vs 검색엔진(elasticsearch)
| 구분 | RDBMS | 검색엔진(elasticsearch) |
| 데이터 저장 방식 | 정규화 | 역정규화 |
| 전문(Full Text) 검색 속도 | 느림 | 빠름 |
| 의미 검색 | 불가능 | 가능 |
| join | 가능 | 불가능 |
| 수정 / 삭제 | 빠름 | 느림 |
텍스트 분석 과정
STEP 1. Whitespace Tokenizing
빈 공백(스페이스)을 기준으로 Tokenizing을 한다.

STEP 2. 대문자를 소문자로 변환
대/소문자 상관없이 검색하기 위해 소문자로 변환하는 작업을 한다.

STEP 3. 불용어(stopwords) 처리
의미상 가치가 없는 단어들을 제거한다.
- example: the, a, an, to, for, at, be, but, by, i, no, the... 등등
STEP 4. 형태소 분석 ~s, ~ing 등을 제거
- jumpin → jump
- jumps → jump
- lazy → lazi happy → happi (happiness와 같은 단어도 검색이 되도록 하기 위해)
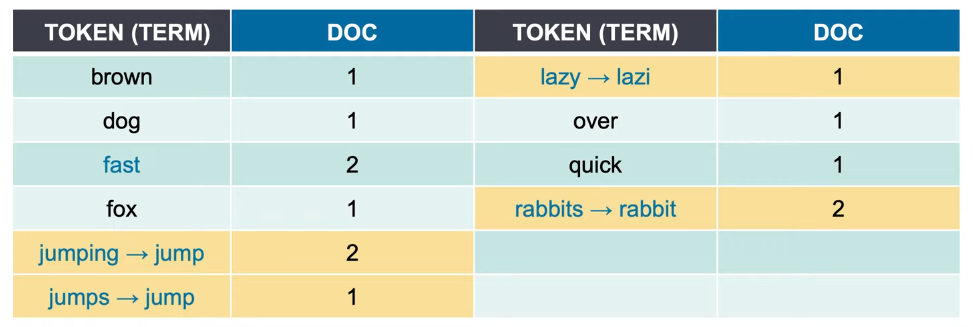
STEP 5. 동의어 처리
Synonym Token Filter를 이용해 동의어 사전을 정의

다른 글
2021/01/22 - [ETC] - MacOSX 에 ElasticSearch 설치하기 (Homebrew 사용)
MacOSX 에 ElasticSearch 설치하기 (Homebrew 사용)
Elastic Search 설치 아래 사이트에서 설치를 진행한다. www.elastic.co/kr/downloads/elasticsearch Download Elasticsearch Free | Get Started Now | Elastic | Elastic Want it hosted? Deploy on Elastic Clo..
memostack.tistory.com
Reference
'ETC' 카테고리의 다른 글
| Virtual Box에 Ubuntu 20.04 VM 생성하기 (0) | 2021.02.18 |
|---|---|
| vscode에서 prettier가 적용되지 않는 경우 (defualt formatter, format on save 설정) (0) | 2021.02.15 |
| MacOSX 에 ElasticSearch 설치하기 (Homebrew 사용) (0) | 2021.01.22 |
| Git 계정 변경, fatal: Authentication failed for (0) | 2021.01.19 |
| MacOS에 Httpie 설치하기 (Homebrew 이용) (0) | 2020.12.02 |
